变秃变强
问题
- 平时大家都在说 ArrayList 查找快,增删慢;LinkedList 查找慢,增删快,但是为什么呢?
- LinkedList 底层实现,如果让你实现一个简单的 LinkedList,你会怎么实现?
- 大家都知道 LinkedList 底层是双向链表,那么你觉得适用于哪些场景?
分析源码
首先还是想来看类注释,总结出以下几点:
- 双向链表实现了
List 和 Deque 接口,实现了所有可选的 List 操作,允许元素为 null;
- 是线程不安全的,
List list = Collections.synchronizedList(new LinkedList(...)) 来实现线程安全;
- 不能保证迭代器的 fail-fast 行为,在不同步的并发情况下,不可能做出严格的保证。fail-fast 仅应用于检测错误。
整体结构
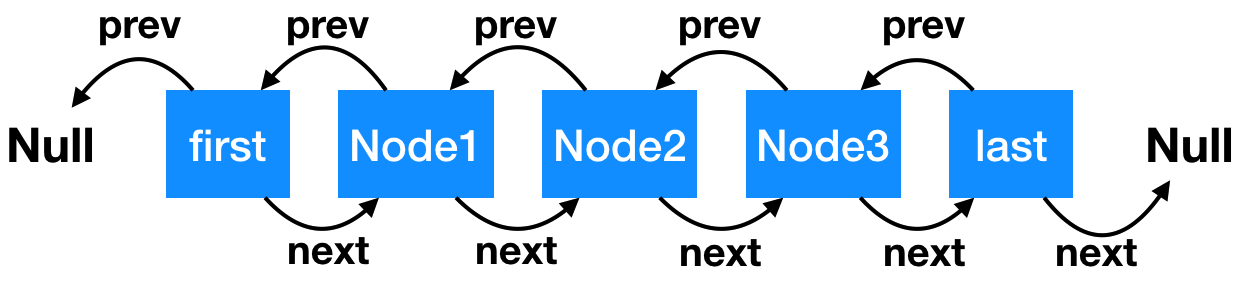
双向链表,又称为双链表,是链表的一种,它的每个数据结点中都有两个指针,分别指向直接后继和直接前驱。所以,从双向链表中的任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点。一般我们都构造双向循环链表。
链表中的元素叫 Node,可以看下源码中的实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
|
从头部新增
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| private void linkFirst(E e) {
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}
|
查找
尾部追加跟头部新增类似,这里就不再讲了。我觉得链表中实现的二分查找的思想,我们是可以借鉴的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| Node<E> node(int index) {
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
|
删除
以删除对应下标的 Node 为例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
E unlink(Node<E> x) {
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
|
迭代器
因为 LinkedList 需要实现双向的访问,Iterator 满足不了。因为 Iterator 只能从前往后遍历,Java 提供了一个新的接口 ListIterator,提供了向前和向后迭代的方法:
| 迭代顺序 |
方法 |
| 从前往后迭代的方法 |
hasNext()、next()、nextIndex() |
| 从后往前迭代的方法 |
previous()、previousIndex()、hasPrevious() |
其实我看了下 ArrayList 也是有实现 ListIterator 接口的,只不过平时没用到,例如我们也可以从前往后查找:
1
2
3
4
5
6
7
8
9
10
11
| public void testListIterator(){
ArrayList<String> list = new ArrayList<>();
list.add("a");
list.add("b");
list.add("c");
ListIterator<String> listIterator = list.listIterator(2);
while (listIterator.hasPrevious()){
String previous = listIterator.previous();
System.out.println(previous);
}
}
|
LinkedList 里的 ListIterator 实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| private class ListItr implements ListIterator<E> {
private Node<E> lastReturned = null;
private Node<E> next;
private int nextIndex;
private int expectedModCount = modCount;
public E next() {
checkForComodification();
if (!hasNext())
throw new NoSuchElementException();
lastReturned = next;
next = next.next;
nextIndex++;
return lastReturned.item;
}
}
|
好的,现在可以回答文中前面几个问题了。
- ArrayList 底层是数组,LinkedList 底层是双向链表
- 对于插入 (add) 和 remove (删除),ArrayList 需要移动目标节点后面的节点 ,System.arraycopy 用来移动节点(native方法)。而 LinkedList 只需要修改目标节点对应的 next 或 prev 属性即可。
- 对于查找操作,因为 ArrayList 是拿数组存的,所以直接根据索引就能取到对应的数据。而 LinkedList 需要从前往后或者从后往前迭代,查找目标数据
PS:对于顺序插入,也就是 ArrayList 不需要扩容,并且是最后一个节点插入,那么就不需要移动节点,因此效率上也不会比 LinkedList 差
最后附上自己实现的 LinkedList 代码地址
